اختبار Kolmogorov-Smirnov للعينة الواحدة
Conditions d’achèvement
|
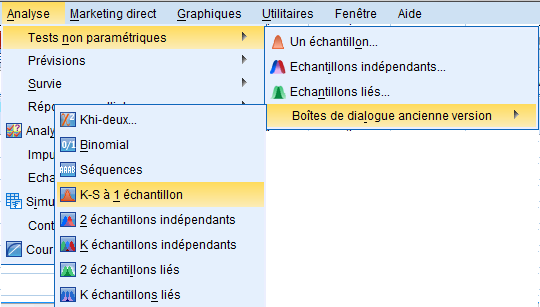
1. ننقر على لائحة التحليل « Analyse »، و التي تحتوي على مجموعة من القوائم الفرعية 2. نحدد القائمة الفرعية مقارنة المتوسطات « Tests non paramétriques » التي تنسدل منها قائمة تضم مجموعة من الأوامر الفرعية، فنختار القائمة الفرعية « boites de dialogues Ancienne version » 3. ضمن هذه القائمة الفرعية ننقر على الأمر المتعلق بمقارنة أكثر من عينتين مستقلتين « K-S à 1 échantillon» ، حيث تبرز لنا علبة الحوار والتي تحمل عنوان هذا الأمر |
 |
|
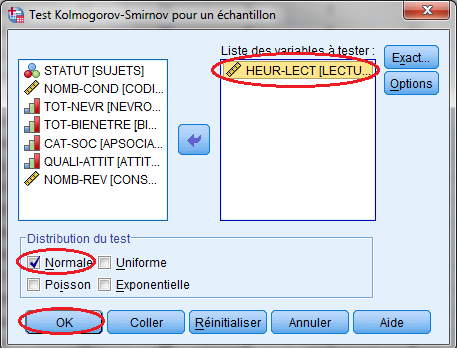
4. نقوم بنقل المتغير المعني بعملية التحليل وليكن في هذه الحالة متغير ساعات القراءة « Heur-Lect » إلى الحيز المعنون ب «Liste des variables à tester » باستخدام السهم الذي يتوسط حيز المتغيرات و حيز التحليل. 5. على مستوى « Distribution du test » نختار أحد البدائل المتوفرة لتوفيق بيانات المتغير المعني بالتحليل لأحد التوزيعات الاحتمالية المتوفرة، وليكن في هذه الحالة التوزيع الاحتمالي الطبيعي، حيث نبقى على الاختيار المؤشر « Normale » بالعلامة « ✔ ». 6. ثم ننقر على « Ok » لتنفيذ عملية التحليل، والتي ستظهر نتائجها على مستوى شاشة عارض النتائج: « Sortie » الخاصة بهذا الاختبار |
 |
|
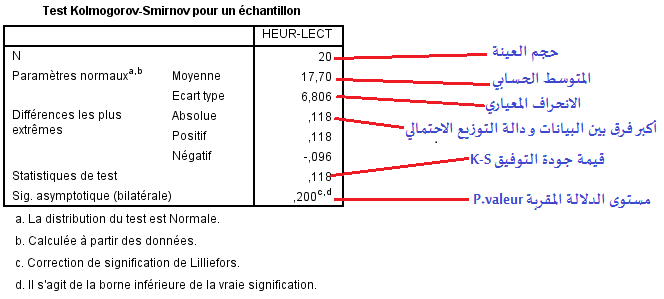
تعرض نتائج التحليل الاحصائي الخاصة بهذا الاختبار على مستوى شاشة عارض النتائج « Sortie » في القسم الأيمن الخاص بنتائج التحليل الإحصائي في جدول واحد يحمل عنوان « Test Kolmogorov-Smirnov pour un échantillon »
و يتضمن الجدول مجموعة من البيانات المرتبطة بتقدير جودة توفيق بيانات متغير القراءة للعينة مع التوزيع الطبيعي، و أهم هذه البيانات حجم العينة المقدر ب (20) و متوسط ساعات القراءة (17.7) بانحراف معياري (6.8)، في حين نجد أن قيمة أكبر فرق دال و دال التوزيع الاحتمالي « Zéta » تقدر ب: (0.11)، بالإضافة إلى قيمة جودة التوفيق « K-S Z » المقدرة ب: (0.11) و قيمة مستوى الدلالة المقربة باتجاهين « P.valeur sig. bilat » تقدر ب:(0.20)، و هذه المعالجة توجهها صياغة الفرضين البديل H1 و الصفري H0 على النحو التالي: H1: بيانات متغير القراءة للعينة لا تتبع خصائص التوزيع الطبيعي H0: بيانات متغير القراءة للعينة تتبع خصائص التوزيع الطبيعي عمليا تبعا لبيانات هذه المعالجة و بناء على قيمة و مستوى الدلالة المقربة«Sig. Asymptotique(bilat)» والمقدرة ب: (0.20) و هي قيمة تجاوزت مستوى الدلالة (α 0.05) ، وفي هذه الحالة نقبل الفرض الصفري H0 و نرفض الفرض البديل H1 ، وعليه نقر بجودة تطابق بيانات العينة في متغير القراءة مع التوزيع الطبيعي، أن توزيع بيانات المجتمع الذي سحب منه العينة يتبع خصائص التوزيع الطبيعي.
|
|
Modifié le: jeudi 10 avril 2025, 11:58